Understanding VAST Data's Erasure Coding Architecture
VAST Data runs three different erasure coding schemes on the same hardware. Metadata uses 3× triplication requiring all replicas to acknowledge writes. Write buffers use N+2 double-parity erasure coding tolerating any 2 failures. The capacity tier employs proprietary LDEC with 146+4 wide stripes.
This architectural choice creates operational asymmetries that affect system behavior during failures. Understanding these trade-offs requires examining what VAST claims, how their algorithms compare to well-documented alternatives, and what operational complexity emerges from multi-tier protection schemes.
The Three-Tier Architecture (Version 5.1+)
Section titled “The Three-Tier Architecture (Version 5.1+)”VAST introduced a significant change in April 2024 with Version 5.1. The SCM write buffer transitioned from 3× mirroring to N+2 double-parity erasure coding, improving write performance by 50-100% while reducing write amplification from 3× to 1.2× [21].
This created three distinct protection mechanisms on shared SCM hardware:
Metadata uses 3× triplication across separate failure domains. Every metadata write must be acknowledged by all three replicas before confirming to clients - not a majority quorum, unanimous agreement.
Write Buffer uses N+2 double-parity erasure coding (typically 6+2, 8+2, or 10+2 configurations). This tolerates any 2 SCM device failures with deterministic availability.
Capacity Tier uses LDEC 146+4 on QLC flash, providing claimed 4-failure tolerance with 2.74% overhead.
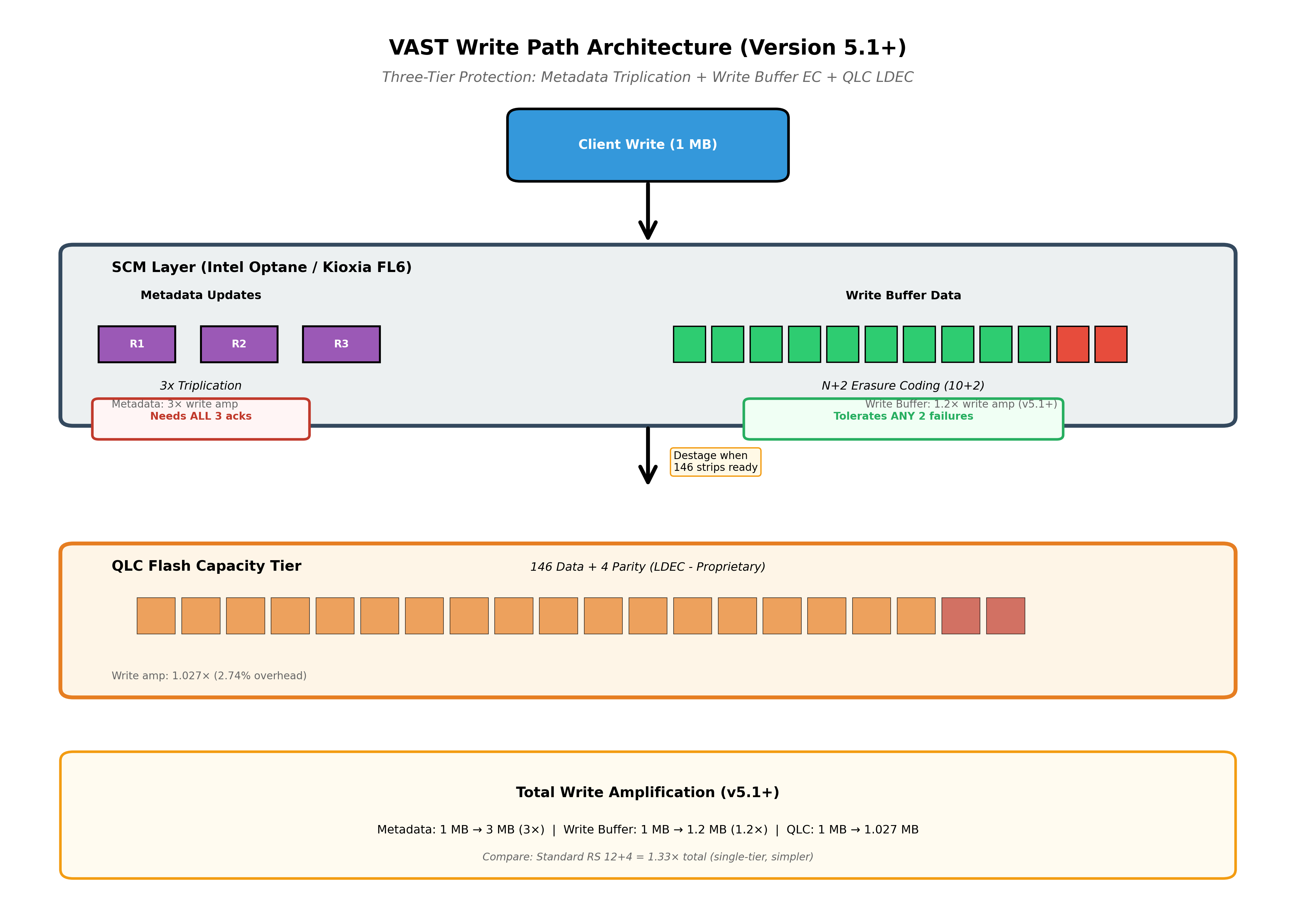 VAST’s write path through three protection tiers with different erasure schemes at each layer.
VAST’s write path through three protection tiers with different erasure schemes at each layer.
The metadata write asymmetry creates a practical concern. When 2 SCM SSDs fail, the write buffer continues operating - N+2 erasure coding handles this scenario. But metadata writes stop. The system needs 3 acknowledgments and only 1 device remains. Result: read-only degraded mode despite functioning write buffer capacity.
VAST acknowledges this challenge: “When any two DBoxes/EBoxes go offline, there is always some risk that those two DBoxes would hold both copies of some write buffer pages or metadata blocks, which could cause the system to go offline as well” [2]. They solved this for write buffers through erasure coding in v5.1. Metadata continues using triplication with all-replicas requirements.
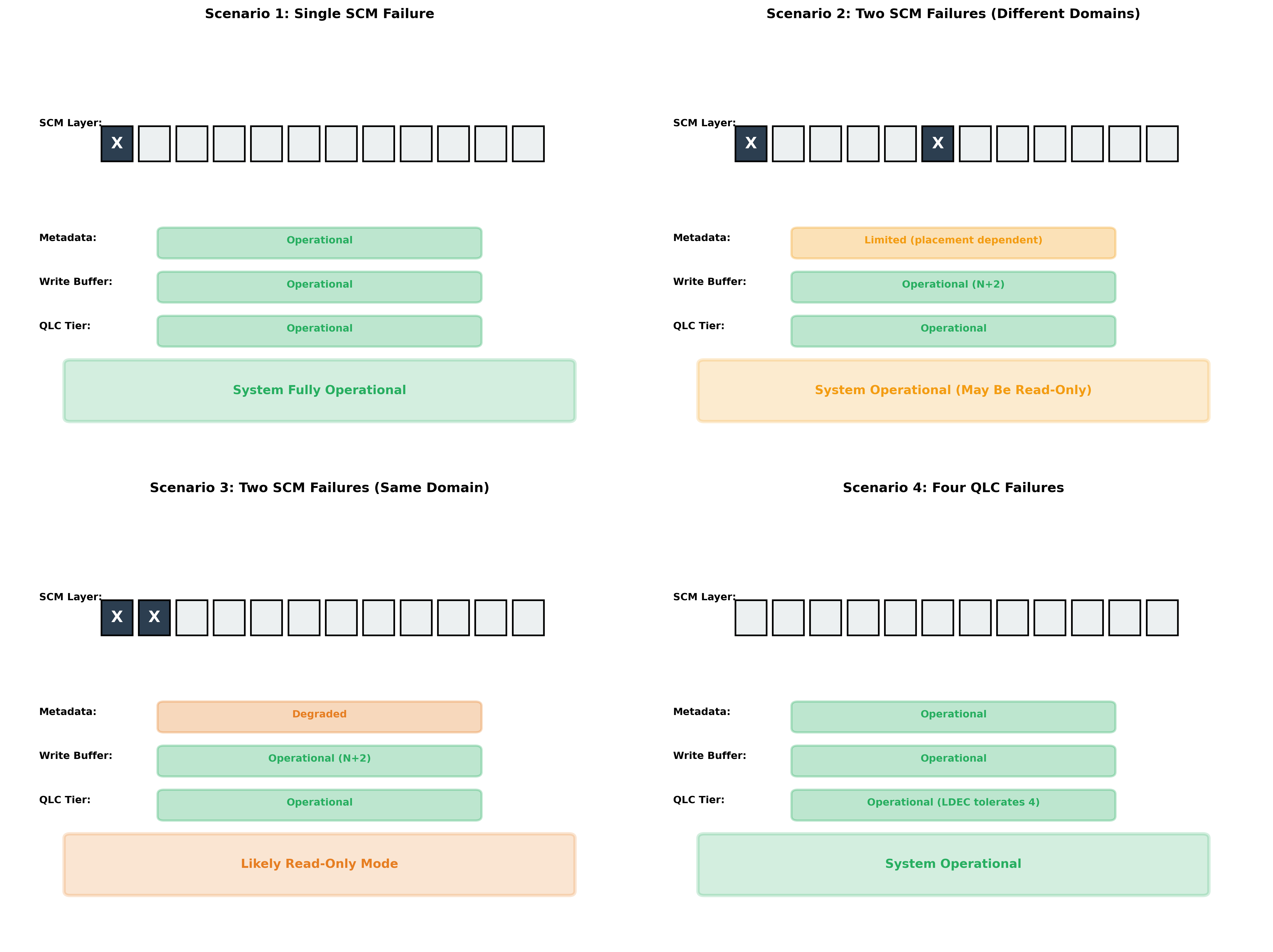 Four failure scenarios demonstrating system behavior. Two SCM failures can trigger read-only mode depending on metadata replica placement.
Four failure scenarios demonstrating system behavior. Two SCM failures can trigger read-only mode depending on metadata replica placement.
 Three protection schemes on shared SCM hardware, each with different failure tolerance.
Three protection schemes on shared SCM hardware, each with different failure tolerance.
You’re debugging different failure math on the same devices. Write buffer availability is deterministic - any 2 failures work. Metadata availability depends on which specific devices fail and where replicas landed.
What VAST Claims
Section titled “What VAST Claims”VAST’s specifications center on 146+4 erasure coding [1][2][3]:
The storage efficiency is 97.33% (146 data + 4 parity = 2.74% overhead). At exabyte scale this saves substantial cost versus 12+4 configurations at 33% overhead. The arithmetic is straightforward. MinIO AIStor at 12+4 uses 33.33% overhead, delivering verifiable 4-failure tolerance with published source code [18]. VAST achieves 2.74% overhead with claimed 4-failure tolerance through proprietary algorithms. The efficiency advantage is 12× better, assuming the failure tolerance claim holds.
The rebuild efficiency claim states “typically 1/4th” of surviving drives for recovery. Traditional Reed-Solomon reads 66-75% of stripes during reconstruction. VAST reads substantially less for single failures through locality optimization.
The word “typically” indicates common-case behavior. For locality-optimized codes, rebuild ratios generally scale with failure count: 25% for 1 failure, 50% for 2, 75% for 3, 100% for 4 [10]. Traditional Reed-Solomon maintains 75% regardless - less efficient for single failures but predictable across all scenarios. VAST’s public materials focus on the single-failure case. Multi-failure rebuild behavior isn’t detailed with the same prominence.
MTTDL is rated at 44 million years, though calculation methodology remains unpublished. Ceph and MinIO publish their MTTDL calculations with underlying assumptions - drive failure rates, rebuild times, correlated failure probabilities. This allows independent verification and adjustment for specific deployment characteristics.
The Algorithm: Why It’s Not Zigzag
Section titled “The Algorithm: Why It’s Not Zigzag”Glenn Lockwood suggested in 2019 that VAST might use “a derivative of the Zigzag coding scheme” [7]. Examining Zigzag codes reveals why VAST must be doing something different.
Zigzag codes, introduced by Tamo, Wang, and Bruck in 2013, are MDS (Maximum Distance Separable) array codes optimized for single node failures [4]. They achieve impressive rebuild ratios - for an r-failure correcting code, the rebuild ratio is 1/r. With 4 parity nodes, that’s 25%.
However, Zigzag codes have fundamental constraints. They achieve optimal rebuilding only when code rate k/n < 0.5. VAST’s 146+4 has k/n = 0.973, violating this by nearly 5× [5]. The required subpacketization for 146+4 Zigzag would be approximately 10^87 - exceeding atoms in the observable universe [6]. Zigzag codes target single systematic node failures, not the 4-simultaneous-failure tolerance VAST markets.
VAST calls their approach “Locally Decodable Erasure Codes” (LDEC). In academic literature, Locally Decodable Codes refer to cryptographic constructions for querying minimal codeword bits [8]. VAST’s patent describes “using free space to improve erasure code locality” without detailed mathematical construction [9].
The algorithm remains proprietary. Without source code or detailed specification, independent verification isn’t possible. MinIO and Ceph publish their Reed-Solomon implementations - anyone can audit the code. AWS S3 uses proprietary implementations but at least employs well-understood algorithms. VAST uses proprietary implementations of novel code families.
Write Amplification Evolution
Section titled “Write Amplification Evolution”Version 5.0 architecture:
- Client writes 1 MB
- 3 MB written to SCM (3× mirroring)
- 1.027 MB written to QLC (146+4 overhead)
- Total: ~3× write amplification, minimal computation
Version 5.1+ architecture:
- Client writes 1 MB
- 1.2 MB written to SCM (10+2 erasure coding)
- 1.027 MB written to QLC (146+4 overhead)
- Total: ~1.2× write amplification, plus CPU cost
The trade-off: VAST now performs erasure coding in the write path rather than simple memory copies. When concurrent writes don’t fill stripes quickly, the system times out after hundreds of microseconds and pads with zeros to maintain latency [21]. Simple mirroring didn’t need timeout mechanisms.
Standard Reed-Solomon systems write directly in erasure-coded form - one pass at ~1.33× for 12+4. VAST performs encoding twice (SCM and QLC) with different algorithms. The approach enables fast write acknowledgment through SCM buffering but adds coordination overhead.
Historical Lessons: Panasas and Isilon
Section titled “Historical Lessons: Panasas and Isilon”This architectural pattern - replicated fast tier buffering writes until destage to erasure-coded capacity - appeared in earlier systems with mixed results.
Panasas used NVRAM buffering writes before destage to RAID on disks [12]. Isilon evolved through generations using NVRAM write coalescing and later SSD-based SmartFlash [13]. Both encountered operational complexity from multi-tier protection. Isilon’s documentation openly discusses “Window of Risk” periods where specific failure combinations during write-buffer transitions can cause data loss [14].
The lesson: NVRAM failure modes proved complex. Battery failures, power cycling during writes, and coordination state management created edge cases requiring firmware updates and procedure changes. Operators reported that failure diagnosis required vendor support more frequently than single-tier architectures.
VAST’s Optane approach (now Kioxia FL6) avoids batteries and provides better endurance. But the architectural pattern - multiple protection tiers, write coordination, destage timing - carries inherent complexity. Debugging requires understanding which tier holds which data and how failures propagate between layers.
Vendor Comparisons
Section titled “Vendor Comparisons”Microsoft Azure uses LRC (12+2+2) for locality benefits and openly states it “is not Maximum Distance Separable and therefore cannot tolerate arbitrary 4 failures” [16]. They document this limitation explicitly, helping customers understand trade-offs.
MinIO AIStor uses configurable Reed-Solomon with published source code [18]. A 12+4 configuration provides 4-failure tolerance in all scenarios, reads 75% during any rebuild, behaves identically for 1st or 4th failure. No conditional statements about “typical” behavior. Ceph operates similarly with well-documented failure modes validated at CERN scale [19].
The trade-off is overhead. MinIO’s 33.33% versus VAST’s 2.74% is 30PB of hardware at 100PB scale. Whether that cost justifies operational simplicity depends on organizational priorities. Training materials are public. Debugging doesn’t require vendor-specific expertise. Failure scenarios are documented in academic papers.
AWS S3 uses proprietary erasure coding (likely 8+4) but employs well-understood algorithms. You can’t audit Amazon’s implementation but the math is established. VAST uses proprietary implementations of novel code families - a different level of opacity.
Operational Considerations
Section titled “Operational Considerations”Wide stripes require careful failure domain configuration. Put too many of 150 shards in one rack and power failures threaten data. Spread too widely and network becomes the bottleneck [7]. VAST’s DBox-HA mode addresses this by limiting stripes to 2 per enclosure, but this reduces stripe width and changes efficiency characteristics [15].
Glenn Lockwood identified potential bottlenecks in VAST’s all-to-all NVMe-oF communication [7]. Every protocol server needs access to every SSD. Linux kernel scaling limits appear around 900+ NVMe-oF targets per I/O server. This works at modest scale but may constrain growth.
The question for evaluating VAST: Does your team have expertise for multi-tier debugging? Can you work effectively with vendor support for proprietary systems? Do you have scale justifying the complexity? Organizations with strong storage engineering teams and multi-petabyte deployments can leverage VAST’s benefits. Those prioritizing operational simplicity may find traditional approaches more suitable.
Migration and Documentation Gaps
Section titled “Migration and Documentation Gaps”VAST characterizes v5.0 to v5.1 upgrades as non-disruptive using rolling restarts. How data migrates from 3× mirroring to N+2 erasure coding isn’t documented publicly. Specific procedures appear behind VAST’s support portal [22].
For customers with Intel Optane, Intel’s 2022 discontinuation raises questions. VAST qualified Kioxia FL6 in 2021, demonstrating forward planning [23]. Procedures for transitioning existing deployments - mixed Optane/FL6 support, proactive migration programs, compatibility matrices - live in support materials rather than public documentation.
This affects how teams plan and train. Can you study failure scenarios before encountering them? Are runbooks public or vendor-provided? The availability of operational information through support channels versus public documentation influences deployment planning and operational independence.
Deployment Questions
Section titled “Deployment Questions”Organizations evaluating VAST benefit from understanding: rebuild ratios for 2, 3, and 4 simultaneous failures (not just single failure), p50/p95/p99 rebuild bandwidth under production load, DBox-HA operational frequency and efficiency impact, write amplification for specific workloads (random 4KB vs sequential), degraded mode performance when operating with failures, MTTDL calculation methodology and assumptions, failure modes where best-case numbers don’t apply, silent corruption detection and verification procedures, independent validation of erasure coding implementation, and migration procedures for data extraction.
These details emerge through vendor engagement and operational experience rather than public specifications. Having clarity on these aspects helps match system capabilities to organizational requirements.
The Core Trade-Off
Section titled “The Core Trade-Off”VAST delivers storage efficiency through architectural complexity. Three protection schemes on shared hardware. Metadata asymmetry creating placement-dependent availability. Proprietary algorithms preventing independent verification. Multi-tier debugging requiring vendor-specific expertise.
At multi-petabyte scale with expert teams, the efficiency gains justify this complexity. The difference between 2.74% and 33% overhead represents millions in hardware cost. Organizations with strong vendor relationships and sophisticated storage operations can leverage these benefits.
But complexity surfaces in unexpected ways. Misconfigured failure domains. Edge cases in metadata-writebuffer interactions. Performance cliffs when write patterns shift. These aren’t theoretical - they’re operational reality in complex systems.
Simpler alternatives trade storage efficiency for operational predictability. A 12+4 Reed-Solomon system costs more in hardware but less in operational complexity, vendor dependency, and expertise requirements. Training is transferable. Debugging uses general storage knowledge rather than vendor-specific internals.
The choice depends on organizational fit. Can your team handle the complexity? Does your scale justify it? Do you have vendor relationships supporting proprietary systems? VAST suits organizations answering yes to all three. For others, traditional approaches remain viable.
VAST has built impressive technology addressing real problems at extreme scale. Understanding where complexity adds value versus where it adds burden helps organizations decide based on actual capabilities rather than theoretical specifications.
References
Section titled “References”[1] VAST Data, “Ensuring Storage Reliability At Scale,” https://assets.ctfassets.net/2f3meiv6rg5s/6LEH8b9Ik3GDFWVrYGNYWP/c937e30f0f76b6f8145b51c6266ab770/vast-resilience-v7.pdf
[2] VAST Data, “Providing Resilience Efficiently: Part II,” https://www.vastdata.com/blog/providing-resilience-efficiently-part-ii
[3] VAST Data, “Platform Whitepaper,” https://www.vastdata.com/whitepaper
[4] Tamo, I., Wang, Z., & Bruck, J. (2013). “Zigzag Codes: MDS Array Codes With Optimal Rebuilding,” IEEE Transactions on Information Theory, https://arxiv.org/abs/1112.0371
[5] “Zigzag Codes Revisited,” arXiv:2509.23090, 2024.
[6] “Cooperative Repair Scheme for Zigzag Codes,” arXiv:2502.19909, 2025.
[7] Lockwood, G. (2019). “VAST Data’s Storage System Architecture,” https://blog.glennklockwood.com/2019/02/vast-datas-storage-system-architecture.html
[8] MIT CSAIL, “Locally Decodable Codes,” https://people.csail.mit.edu/dmoshkov/courses/codes/LDC_now.pdf
[9] U.S. Patent 11,150,805, “System and method for using free space to improve erasure code locality,” Inventor: Yogev Vaknin (VAST Data), May 2019.
[10] Balaji, S.B., et al. (2018). “Erasure Coding for Distributed Storage: An Overview,” arXiv:1806.04437.
[11] Storage Review, “VAST Data Ceres Data Nodes with SCM,” https://www.storagereview.com/review/vast-data-ceres-data-nodes-launched-with-bluefield-e1-l-and-scm-on-board
[12] Panasas, “PanFS 9: Architectural Overview,” https://www.panasas.com/wp-content/uploads/2022/08/Panasas_White-Paper-panfs-9-architectural-overview.pdf
[13] Dell Technologies, “PowerScale OneFS SmartFlash,” https://www.delltechnologies.com/asset/en-us/products/storage/industry-market/h13249-wp-powerscale-onefs-smartflash.pdf
[14] Dell Support, “How to Determine if Cluster is in Window of Risk,” https://www.dell.com/support/kbdoc/en-us/000018892/
[15] VAST Data, “Rack-Scale Resilience,” https://www.vastdata.com/blog/introducing-rack-scale-resilience
[16] Huang, C., et al. (2012). “Erasure Coding in Windows Azure Storage,” USENIX ATC. https://www.usenix.org/system/files/conference/atc12/atc12-final181_0.pdf
[17] “Design Considerations and Analysis of Multi-Level Erasure Coding,” ACM SC 2023. https://dl.acm.org/doi/10.1145/3581784.3607072
[18] MinIO, “AIStor Architecture,” https://min.io/product/erasure-code
[19] CERN, “EOS - Disk Storage System,” https://eos-web.web.cern.ch/eos-web/
[20] Cloudian, “HyperStore Architecture,” https://cloudian.com/products/hyperstore/
[21] VAST Data, “We’ve Got the Write Stuff, Baby,” https://www.vastdata.com/blog/weve-got-the-write-stuff-baby
[22] VAST Data, “Version 5.1 Upgrade Guide,” https://support.vastdata.com/s/article/UUID-4e7a36af-3b62-04e5-12d0-9629b380b084
[23] “VAST Data Lessens Optane Dependency,” Blocks and Files, November 2021. https://blocksandfiles.com/2021/11/05/vast-data-lessens-optane-ssd-dependency/
Analysis based on publicly available information, academic research, and VAST’s technical documentation. The proprietary LDEC implementation cannot be independently verified without source code access. Critical operational procedures remain behind VAST’s support portal.
StorageMath analyzes all vendors with equal rigor. Found an error? Submit evidence and we’ll update.